
AI기술의 발전 속도는 어마무시하다. 학계는 이러한 기술 발전을 이루기 위한 핵심요소 중 하나인 Multi-modality을 추구한다. 멀티모달을 훌륭하게 구현한 BEiT-3를 여러분들께도 소개하겠다.
Multi-modality or Multimodal
모달리티(modality)는 사전적으로 '양식, (인체의 감각적) 양상'이라고 한다. 실질적인 의미의 modality는 기계가 이해할 수 있는 요소 혹은 요소들과 상호작용하는 방법이다. 텍스트, 이미지, 음성, 그리고 물리적 움직임 등 여러 채널의 요소들을 이해하고 학습할 수 있는 특성을 멀티모달(Multi-modal)이라고 한다. 기존의 AI와 다르게 Multi-modal AI 혹은 모델은 비교적 폭넓은 종류의 여러 데이터를 학습하고 그들 사이의 관계를 추론한다.
BEiT-3
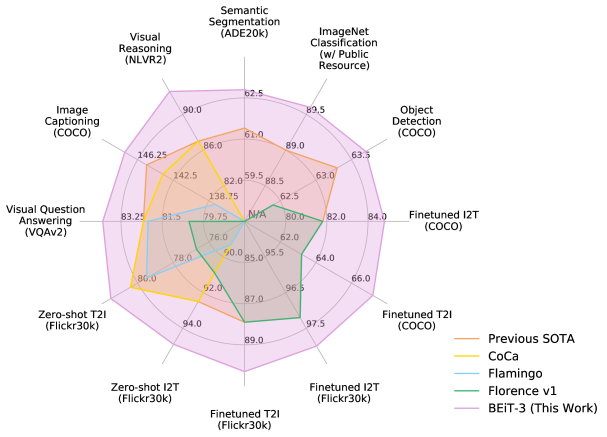
결론부터 말하자면 BEiT-3 모델은 다른 모델과 비교했을 때 vision, 그리고 vision-language 부문에서 모두 더 나은 성능을 보인다. Vision 문제에서 지금은 더 강력한 모델에게 역전되었지만, 여전히 준수한 스코어를 보이고 있으며 vision-language, 특히 VQA에서는 SOTA수준의 성능이다.
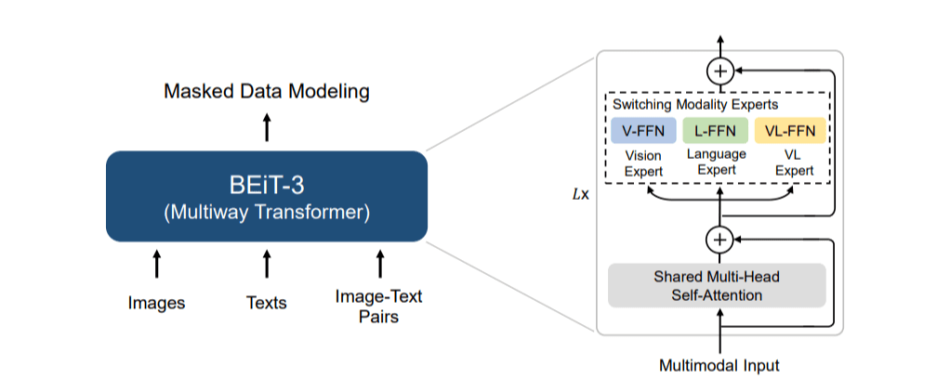
BEiT-3의 가장 핵심적인 novelty는 범용성에 초점을 둔다. 다양한 modality의 데이터셋에 두루 적용할 수 있는 모델을 지향하고 있다. 초기 BEIT는 NLP에서 보편적으로 사용되어 온 BERT를 image에 적용하여 풀 수 있었고 BEiT-3에 와서 image와 text, 그리고 image-text pairs를 pre-training하였다. 이를 통해 imglish(image+english) 문제의 해결에 더욱 가까워졌고 multi-modality의 실현을 일정 수준까지 올려놓았다.
Multi-modality 개념을 포함해 AI 분야에서는 언어, 시각 및 다중 모드 pre-training의 대규모 융합이 등장하고 있다. 그러한 작업의 일환으로 BEiT 모델이 탄생하였다. 본문에서는 BEiT-3를 범용 멀티모달 foundation model이라 소개하고 있다. 향후 BEiT-3의 scaling-up을 통해 다양한 downstram task에 전이될 수 있을 것으로 보인다.
해당 논문 : Image as a Foreign Language: BEiT Pretraining for All Vision and Vision-Language Tasks
'Software Engineering' 카테고리의 다른 글
| [Python 문제 풀이] 프로그래머스 '혼자서 하는 틱택토' (0) | 2023.03.12 |
|---|---|
| [Python 문제 풀이] 프로그래머스 '미로 탈출' (0) | 2023.03.06 |
| vscode.dev에서 원격 Jupyter 서버 연결하기 (0) | 2023.03.05 |
| [Python 문제 풀이] 프로그래머스 '호텔 대실' (0) | 2023.02.17 |
| [Python 문제 풀이] 프로그래머스 '빛의 경로 사이클' (0) | 2023.02.09 |